
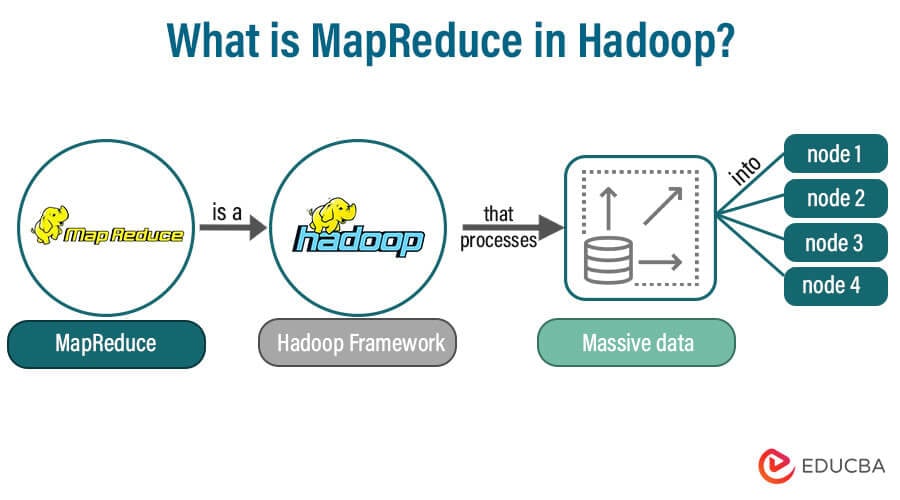
大数据 | MapReduce超级详细版
前情提要
准备工作
装好IDEA
创建好Maven项目 | ArchType-1 | ver 1.0.0
创建Maven项目
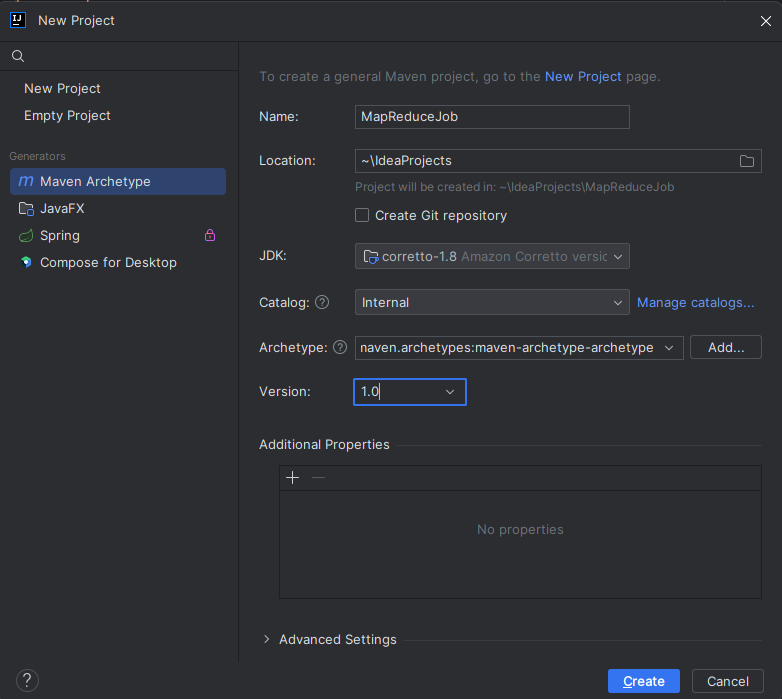
Pom.xml编写
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>在pom.xml 的</project>语句块前加上上述内容。
并点击侧边栏Maven的同步按钮
开始创建项目目录
对项目文件夹右击 -> New -> Directory -> src/main/java
创建软件包,可以任意取名,但是不能有中文,示例: com org cn
题目样例(大概)
筛掉“城市”为空的数据和“月份”为空的数据
取出空气质量(平均)
向Reducer传入空气质量
Reducer处理完后输出
cityName,Counts的结果
开始实操
文件结构
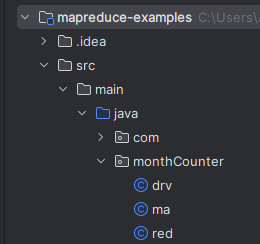
Driver类
代码示例
package monthCounter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class drv {
public static void main(String[] args)
throws Exception{
Configuration conf = new Configuration();
String[] rargs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = Job.getInstance(conf, "monthCounter");
job.setJarByClass(drv.class);
job.setMapperClass(ma.class);
job.setReducerClass(red.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
FileInputFormat.setInputPaths(job, new Path(rargs[0]));
FileOutputFormat.setOutputPath(job, new Path(rargs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
按行解析
package monthCounter;
import org.apache.hadoop.......Java类头部内容,package表明所在的软件包,import语句可以导入需要的软件包,在编写时通过提示内容可以自动补充,但一定要注意引入的包为org.apache.hadoop.*的,除了System/Math/Exceptions ,防止后续程序报错。
Configuration conf = new Configuration();
String[] rargs = new GenericOptionsParser(conf, args).getRemainingArgs();两行,定义配置文件,获取args参数,形似Python sys.argv ,但是rargs指的是剩余的,即为筛选掉原先的conf内容后的数据(getRemainingArgs),是一个字符串列表,可以作为输入和输出目录
备注:
启动命令的 hadoop jar xxx.jar com.xxx.driver /path/to/your/input /path/to/your/outputhadoop后面的就是参数,conf与getRemainingArgs就是筛选掉/path....../output前的所有内容,保留InputPath和OutputPath
Job job = Job.getInstance(conf, "monthCounter");
job.setJarByClass(drv.class);
job.setMapperClass(ma.class);
job.setReducerClass(red.class);工作创建于类定义,创建一个job,并指定Driver类、Mapper类、Reducer类。
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);显而易见,定义Mapper/整个程序输出与文本输出的类型。
注:为什么要用这样的方式定义?因为MapReduce的IO是及其类似K,V键值对的形式的。后面会讲到。
FileInputFormat.setInputPaths(job, new Path(rargs[0]));
FileOutputFormat.setOutputPath(job, new Path(rargs[1]));定义输入与输出路径,是剩余args的[0]与[1],与上文对应。
System.exit(job.waitForCompletion(true) ? 0 : 1);启动job,开始MapReduce进程,并在完成后退出Java进程。
Mapper类
代码示例
package monthCounter;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ma extends Mapper<LongWritable, Text, Text, FloatWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String[] fields = value.toString().split(",");
String city = fields[0];
if (!city.equals("city") && !city.isEmpty())
{
Float air = Float.parseFloat(fields[7]);
context.write(new Text(city), new FloatWritable(air));
}
}
}按行解析
Mapper类通常不太需要太多的复杂操作,以键值对的形式输入输出即可
public class ma extends Mapper<LongWritable, Text, Text, FloatWritable> {LongWritable是行数数值,LongWritable是org.apache针对Hadoop开发的一个高效率封装软件包,对应long的数据类型,Text对应String类型,但不能直接使用。
此处解释:扩展Mapper类(import org.apache.hadoop.mapreduce.Mapper;) 输入输出分别为:行号、文本,文本、浮点数值
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{@Override开始继承Mapper类,map(此处必须取名为map,要不然会出错。)
定义LongWritable类型 key作为行号,Text类型value作为数值(文本),以及引入上下文。注意抛出IOException和InterruptedException ,否则Context上下文输出时可能会遇到错误。
String[] fields = value.toString().split(",");从value开始读取,并转为String字符串,再用","分割(CSV格式的默认分隔符)
String city = fields[0];定义一个字符串city为fields的第[0]个索引值,对应city城市值。
if (!city.equals("city") && !city.isEmpty())
{
Float air = Float.parseFloat(fields[7]);
context.write(new Text(city), new FloatWritable(air));
}若城市值不为列名("city")或空(必须清除列名与空数值,否则会报错)
然后用Java自带封装类型Float定义一个air,再使用Float的解析器将field[7](空气质量相应的字符段)解析为Float类型,即浮点小数,当然也可以用Double,不过没有任何必要,空气质量指数不可能不在Float的范围。
最后new一个text和floatwtb,写入上下文(<String, Float>)。
Reducer类
代码示例
package monthCounter;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.*;
import java.lang.Math;
public class red extends Reducer<Text, FloatWritable, Text, FloatWritable> {
private final Map<String, Float> map = new HashMap<>();
@Override
protected void reduce(Text text, Iterable<FloatWritable> value, Context context)
{
List<Float> data = new ArrayList<>();
float mean = 0;
int counts = 0;
for(FloatWritable i: value) {
data.add(i.get());
mean += i.get();
counts += 1;
}
mean = mean / counts;
float all = 0;
for(Float i: data) {
all += Math.pow(i - mean, 2);
}
all = (float) Math.pow(all / counts, 0.5);
map.put(text.toString(), all);
}
@Override
protected void cleanup(Reducer<Text, FloatWritable, Text, FloatWritable>.Context context)
throws IOException, InterruptedException
{
List<Map.Entry<String, Float>> list = new ArrayList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Float>>() {
@Override
public int compare(Map.Entry<String, Float> o1, Map.Entry<String, Float> o2) {
int n;
n = o2.getValue().compareTo(o1.getValue());
if(n != 0) {
return n;
}
return o2.getKey().charAt(0) - o1.getKey().charAt(0);
}
});
for (Map.Entry<String, Float> i: list) {
context.write(new Text(i.getKey()), new FloatWritable(i.getValue()));
}
}
}
按行解析
public class red extends Reducer<Text, FloatWritable, Text, FloatWritable> {引入Mapper的值,定义输出文本的值(文本,浮点、文本,浮点)
private final Map<String, Float> map = new HashMap<>();建立一个Map,用于存放城市信息与空气质量信息,注意只能用Java的自带封装类型,否则会出问题。
@Override
protected void reduce(Text text, Iterable<FloatWritable> value, Context context)
{继承reduce类,Iterable<FloatWritable> value 是创建一个名为value的FloatWritable可迭代对象。
List<Float> data = new ArrayList<>();
float mean = 0;
int counts = 0;
for(FloatWritable i: value) {
data.add(i.get());
mean += i.get();
counts += 1;
}创建一个data对象临时存放,value实际上只能被迭代一次
map.put(text.toString(), all);此处的Reducer作用是存入map中,而不是直接写入上下文。map可以用来sort排序。
@Override
protected void cleanup(Reducer<Text, FloatWritable, Text, FloatWritable>.Context context)
throws IOException, InterruptedExceptioncleanup在此处充当排序器和输出,所以需要抛错和引入上下文。
List<Map.Entry<String, Float>> list = new ArrayList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Float>>() {
@Override
public int compare(Map.Entry<String, Float> o1, Map.Entry<String, Float> o2) {
int n;
n = o2.getValue().compareTo(o1.getValue());
if(n != 0) {
return n;
}
return o2.getKey().charAt(0) - o1.getKey().charAt(0);
}
});排序部分,用List才能排序。
手动编写排序器:n是o2.getValue()与o1.getValue()排序,返回值只有0/1,代表两者是否相同,倒序排序。
若 n为0,if内的return不执行,跳到下面的内容,但是下方使用compareTo更好,我没改。
for (Map.Entry<String, Float> i: list) {
context.write(new Text(i.getKey()), new FloatWritable(i.getValue()));
}循环一次list,写入上下文,程序结束。
